用人話解讀什麼是 Physical AI

抱歉讓大家久等了!最近真的有點小忙,沒能第一時間更新最新動態。我相信關於 CES 的各種黑科技,大家這幾天肯定已經被新聞和網路資訊轟炸過了。所以今天這篇我不談那些生硬的規格參數,我想發揮我的強項,用最白話、最簡單的方式,帶大家看看這次 CES 到底發生了什麼事,以及這對我們有什麼意義。

2026 年 1 月 6 日,拉斯維加斯 CES。
黃仁勳在台上拋出一句很有張力的話:
「Physical AI 的 ChatGPT 時刻近在眼前」。
這句話聽起來很玄,但其實很好懂:
ChatGPT 讓 AI 學會了在螢幕裡陪你聊天。
Physical AI 則是讓 AI 學會了長出手腳,在現實世界幫你做事。
從「出一張嘴」到「動手做事」,AI 正準備跨出螢幕。但要讓機器人像人類一樣靈活,這個故事得從 60 年前的一面「鏡子」說起。

第一章:鏡子的誕生
1. 實體鏡子:NASA 的救命分身
早在 1960 年代,NASA 就遇到一個難題:
「太空船飛到宇宙去,萬一壞了怎麼辦?」地面無法直接干預,必須提前預測所有可能的問題。
他們的解決方案很簡單:造兩台一模一樣的飛船。
一台飛上天。
一台留在地面。
地面的飛船用來模擬太空中的各種情況。
這就是「孿生」概念的始祖——用一個複製品來映射真實世界。
2. 數位鏡子:從密西根大學到 NASA
但造兩台飛船實在太貴了。到了 2002 年,密西根大學的 Michael Grieves 教授提出了「Digital Twin」也就是數位孿生的概念。
到了2010 年,NASA 正式採用,定義為「集成多物理量、多尺度的模擬」。
簡單來說,就是把那台地面的「實體飛船」,搬進了電腦裡,變成「虛擬飛船」。但核心邏輯沒有變:「用一個虛擬世界來映射、模擬、預測真實世界」。
3. 鏡子的五段進化史
這面鏡子在過去十幾年,偷偷進化了五次。每一次進化鏡子都變得更聰明一點:
第一階段:描述性孿生 (2010-2015) 👁️
能力: 實時監控。
OS: 鏡子告訴你:「你看,現在溫度是 30 度。」
第二階段:診斷性孿生 (2015-2018) 🩺
能力: 異常檢測。
OS: 鏡子告訴你:「你發燒了,這溫度不正常。」
第三階段:預測性孿生 (2018-2022) 🔮
能力: 趨勢預測。
OS: 鏡子告訴你:「再這樣下去,明天這台機器會壞掉。」
第四階段:決策性孿生 (2022-2024) 💡
能力: 優化建議。
OS: 鏡子告訴你:「建議你現在把風扇開大一點,就能避免過熱。」
第五階段:自主性孿生 (2024-至今) ⭐
能力: AI 訓練與行動。
OS: 鏡子不再只是給你建議,它變成了 AI 的訓練場。
但請注意,無論前四個階段怎麼厲害,它始終是一面「鏡子」,它只能模擬、預測、建議,不能直接行動。直到第五階段事情才有了轉機。

第二章:鏡子裡的 AI
鏡子準備好了,但住在鏡子裡的 AI 還沒準備好。
我們現在熟悉的 ChatGPT、Gemini、Grok、Midjourney,其實都是「Internet AI」。它們就像是住在伺服器裡的超級大腦,雖然博學多聞,但它們沒有身體,只能活在鏡子(螢幕)裡。
輸入是文字、圖片
輸出也是文字、圖片、代碼
一切發生在雲端或伺服器
而黃仁勳說的就是要讓這些大腦長出身體,從鏡子裡走出來,指的是「 Physical AI」, 也是我們常聽到的另一個詞:「Embodied AI 具身智能」。
兩者關係可以這樣理解:
Embodied AI 更像研究領域的說法:強調「AI 有身體,需要感知—行動閉環」
Physical AI 更像產業界的說法:強調「把具身能力工程化、規模化,真正部署到車、機器人、工廠裡」
它屬於另一條路:現實 AI。
它面對的是攝影機、雷達、力覺、觸覺、定位等感測器;輸出的是油門、煞車、轉向、機械臂抓取、機器人移動。
但這件事超級難!現實世界不像螢幕世界那麼乖。
光照會變,地面會滑,物體會遮擋;一次摔倒可能是真金白銀的損壞;今天在倉庫學會的動作,換到家裡也許立刻失效。
我們可以想成:
讓一個只在教科書上學過滑雪的人,直接站上真正的滑雪道上。理論懂,不代表腳就會。
第三章:把鏡子世界變成「訓練場」
NVIDIA 找到的破解方法,就是把那面進化到第五階段的「鏡子」,變成「AI 健身房」。

既然在現實世界練機器人太貴、太慢、通用性又差,那就讓 AI 在虛擬世界裡練!
就像電影「駭客任務」或是「奇異博士」用時間寶石預測未來一樣:
打造虛擬工廠/道路:在電腦裡蓋一個跟真實世界一模一樣的環境(數位孿生)。
瘋狂試錯:讓 AI 機器人在裡面摔倒一萬次、撞車一千次,反正虛擬的撞壞了不心疼(解決試錯成本)。
時間加速:電腦裡的一天可以模擬現實的一年(解決時間延遲)。
出關:練好了,再把這套 AI 系統安裝到真實的機器人身上。
實際應用:
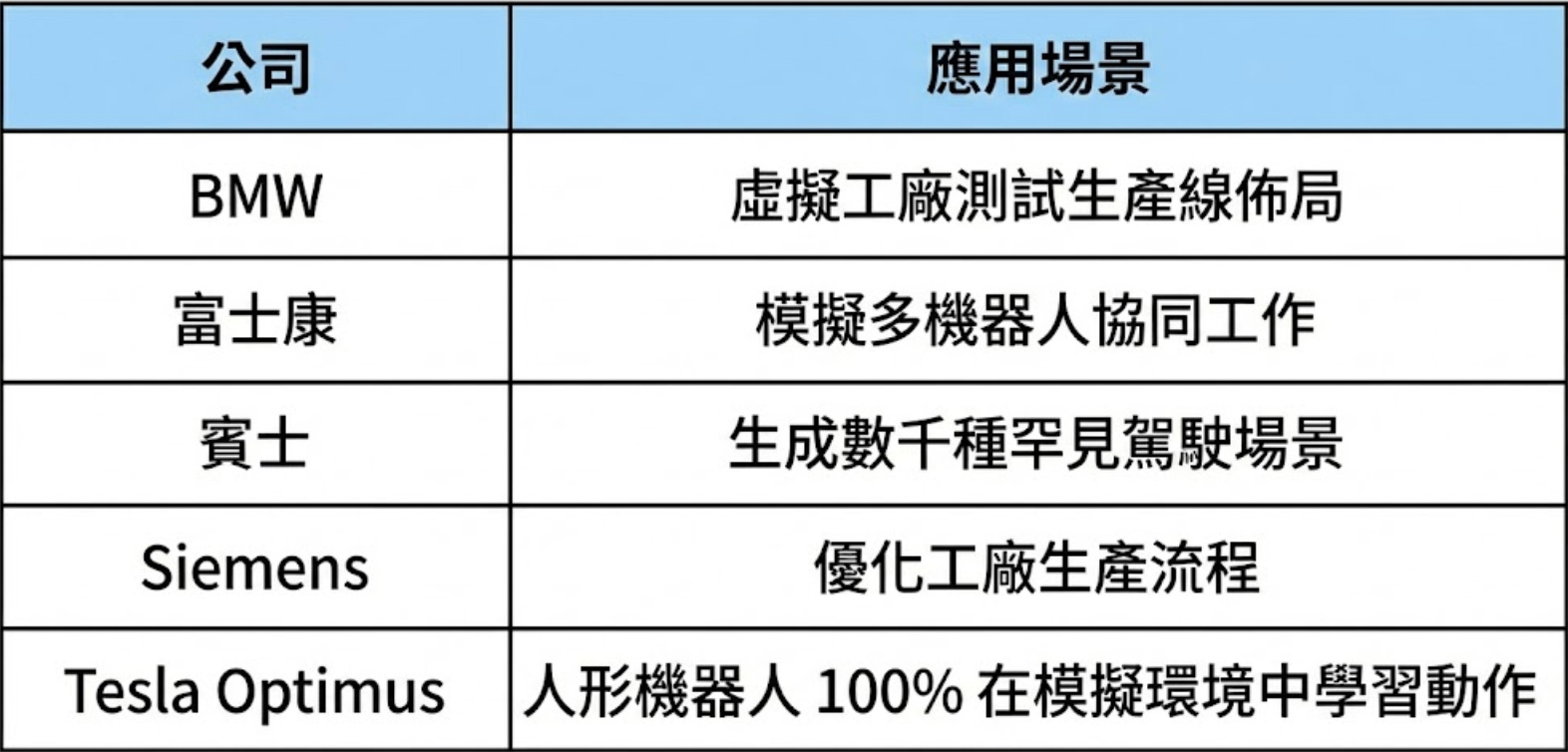
這在業界被稱為 Sim-to-Real 仿真遷移,是目前解決機器人訓練核心的技術路徑。
這就是關鍵轉折點,以前的數位孿生是用來「監控」現狀的;現在的數位孿生,變成了生成 AI 動作的「訓練場」。

第四章:Alpamayo 讓自動駕駛「先想清楚再動手」
很多人談自動駕駛,會以為關鍵是「看見路」,但真正難的往往是「怎麼判斷」。
紅燈很好處理:停。
麻煩的是那些極端案例的突發狀況,那些「不寫在交規裡但天天發生」的現場環境:
前方紅燈,但後方救護車逼近?
施工臨時改道,路權規則變得不清晰?
行人站在路邊猶豫,像要走又像不走?
對向車突然搶道,我們該不該讓道?
人類開車其實一直在做三件事:看懂現場、 判斷風險 、選擇路徑。
而在 CES 2026 登場的 Alpamayo,我們可以用一句話把它講給不懂 AI 的朋友聽:
它把自動駕駛從「遇到 A 做 B」這種死規則,推向「理解語境、預判風險、再做動作」。
就像人腦的思考步驟:
看清楚:路口、號誌、車流、行人位置。
猜風險:誰可能突然變線?誰可能闖入?哪裡最不確定?
選策略:減速、保持距離、給自己留退路。
執行:平順地做出動作,並隨時準備修正。
但我們也要把底線講清楚,避免大家誤會:
Alpamayo 更像「研發與驗證的開放底座」,而不是「一鍵上路的完整自動駕駛系統」。它包含了一個開源的基礎模型、一套閉環測試工具,以及一份針對長尾情境的資料庫。目的是提供從 0 到 1 的基礎方法,讓更多團隊能完成 1 到 100 ,並做出像樣的原型,更快完成驗證。
第五章:它會直接挑戰 Tesla / Waymo 嗎?
我知道講到這裡,大家心裡一定在想:「那 Tesla 的 FSD 呢?Google 的 Waymo 呢?NVIDIA 也要跳下來跟他們打嗎?」
畢竟這兩位是目前的雙雄:
Tesla FSD:路上跑的車最多,強調靠「純鏡頭」的視覺方案就能開遍天下。
Waymo:技術最穩,車頂頂著一堆雷達,已經在美國好幾個城市真的在當「無人計程車」載客了。
但如果我們認為 NVIDIA 要跟他們「互打」,那是把「平台」和「產品/服務」混在一起看了。用一個現實世界的類比比較容易講清楚:
Nvidia Alpamayo 像安卓系統:提供開放平台+工具鏈,讓更多人更容易做出「可用的自駕能力」。
Tesla 像蘋果 iOS:走軟硬一體的產品路線,靠規模與迭代速度把體驗做出來。
Waymo 像 Uber:它賣的不是功能,而是城市裡的出行服務,核心是營運、安全與許可。
換句話說:
1. NVIDIA 在搶什麼?
它在搶的是「研發入口」,讓產業的更多玩家,在同一套工具鏈與標準之上加速前進。這會帶來一種間接壓力:當研發門檻被拉低,追趕者會變多,追趕速度會變快。
2. Tesla 的護城河是什麼?
它更像一個大規模產品飛輪:車隊規模、資料回流、快速 OTA、持續迭代。它的優勢不只是模型,而是「把技術變成消費級體驗」的節奏感。
3. Waymo 的護城河是什麼?
Waymo 的難點不在「把模型訓出來」,而在「把車隊在城市裡長期跑起來」。監管許可、安全論證、事故責任、維運成本,這些才是它最硬的壁壘。
Alpamayo 改變的是「研發速度與標準化」,它會讓更多玩家拿到入場券;但要真正複製 Waymo 的城市級營運能力,Tesla 的整套馬斯克產品體驗,遠不止開源模型這麼簡單。
結語:為什麼是現在?因為成本曲線正在下墜
Physical AI 要在現實世界動起來,本質上需要兩件事同時成熟:
有足夠好的訓練場(數位孿生+模擬+資料)。
推理成本夠低、延遲夠小(才能即時決策、應對突發)。
當算力平台持續進化、推理成本持續下降,Physical AI 才會從「少數人的昂貴玩具」,變成「可規模複製的產業工具」。
從 NASA 當年做兩台飛船開始,人類花了幾十年把「鏡子世界」做得越來越像現實。
現在,變化來了——這個鏡子世界不再只是鏡像,而開始成為訓練場。
數位孿生給了 Physical AI 一個可控的練習空間。
Physical AI 讓數位孿生從「看懂世界」,走向「改變世界」。
如果說過去十年是「AI 學會表達」,
那接下來十年更像是「AI 學會行動」。
從虛擬到現實,從對話到行動,AI 的下一個十年已經開始了。
P.S:今天的文章主要在講概念與趨勢。大家關心的 Physical AI 和 Embodied AI 等等更深一步的硬核解讀,我會在找時間補上,敬請期待哈!
數位孿生還 有點像影分身之術的概念…
哈哈!成为了我给我儿子的睡前故事!太棒了!多来点白话ai系列!