GTC 2026 AI 基建時代的總包工頭


在 2026 年 3 月 16 日的 GTC 大會上,當黃仁勳穿著招牌黑色皮衣現身 SAP 中心時,台下近萬名觀眾已有共識。這一次老黃要講的不是某個單一晶片,而是一整套 AI「全家桶」。
會前市場早已高度期待,針對黃仁勳此前預告「前所未見的晶片」,業界普遍推測為導入台積電 1.6 奈米製程及光通訊技術的下一代 Feynman 架構。
今天揭曉的 Feynman 架構、Vera Rubin 平台的量產進展,以及面向企業級自主代理的開源平台 NemoClaw,不過是這座基礎設施落地所需的「鋼筋水泥」。黃仁勳用兩個多小時向市場證明一件事,輝達早已不是那個賣顯示卡的公司,現在的輝達是一家為「數兆美元 AI 基建時代」搭建技術堆疊的「總包工頭」。
回顧 CUDA 20 年
演講剛開始,黃仁勳回溯了 CUDA 架構誕生 20 年的演進歷程。他將 CUDA 生態定義為輝達一切業務的「中心」,並直言 CUDA 是「真正難以複製的壁壘,是底層的安裝基數」。
黃仁勳回憶道「二十年來,我們一直致力於這種革命性架構,單指令多執行(SIMT),讓開發者編寫的擴展程式碼能夠輕鬆生成多執行應用,程式設計難度遠低於傳統方法。」他特別提到近期引入的「tiles」(核心程式設計塊)功能,目的是幫助開發者調用 Tensor Core 以及支撐當前 AI 的數學結構。
如今,圍繞 CUDA 已形成龐大的工具鏈生態。數千種工具、編譯器、框架和函式庫;僅開源領域就有數十萬個公開專案。「CUDA 真正融入了每一個生態系,」黃仁勳說,「這張圖,基本上描述了 100% 的媒體戰略,你們從一開始就看我講這張幻燈片。」

黃仁勳將這套邏輯總結為「飛輪效應」
「CUDA 的安裝基數,是飛輪加速的原因。安裝基數吸引開發者,開發者創造新演算法,帶來技術突破。這些突破催生全新市場,圍繞它們形成新的生態,更多公司加入,進而擴大安裝基數。」
背後的邏輯很簡單,CUDA 支援的應用程式範圍足夠廣,覆蓋 AI 生命週期的每一個階段。一旦安裝 NVIDIA GPU,它的使用壽命夠長。這也是為什麼六年前出貨的 Ampere 架構,在雲端上的定價反而在上漲。這套動態機制讓 NVIDIA 降低了計算成本,最終催生新的增長。(應該是在講給大空頭 Michael Burry 聽)
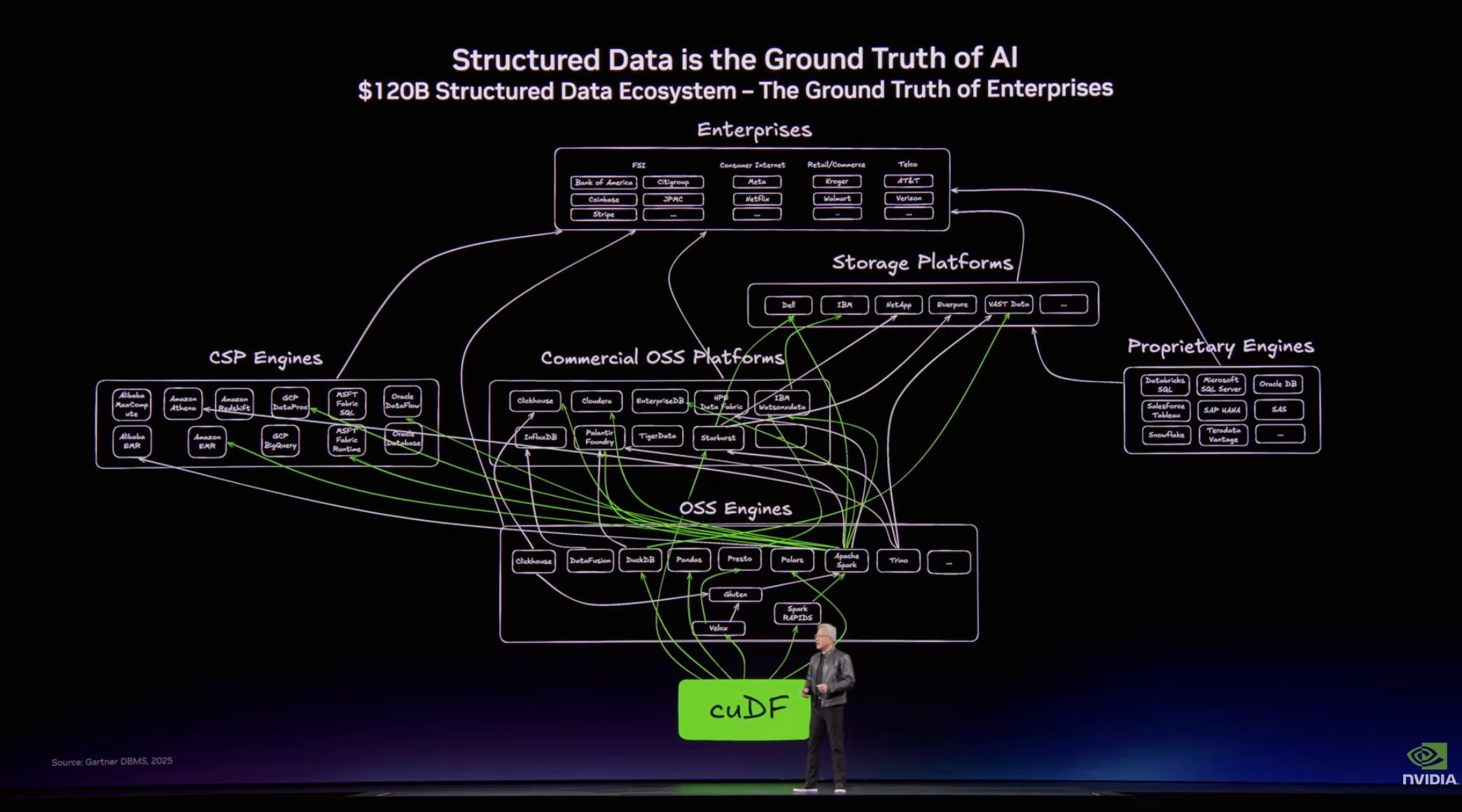
為數據處理打造新的軟體庫
演講中,老黃提到上面這張圖是本場演講中最重要的一張圖,因為裡面提到了輝達為資料處理打造的新的核心軟體庫。老黃在演講中談到,隨著 AI 的快速發展,全球資料處理體系正迎來一次變革,其中最核心的變化,是結構化資料與非結構化資料的全面加速。
黃仁勳指出,長期以來企業運算的基礎建立在結構化資料之上。無論是 SQL、Spark、Pandas 等技術體系,還是諸如 Snowflake、Databricks、Amazon 的 EMR、Microsoft 的 Azure Fabric,以及 Google 的 BigQuery 等大型資料平台,本質上都在處理一種核心資料結構「資料框」(DataFrame)。這些資料框可以被理解為巨型電子表格,承載著企業營運和業務決策所依賴的關鍵資訊,是企業運算體系中的「事實來源」。 過去,對結構化資料的加速主要是為了提升企業級的資料分析效率,讓運算任務完成得更多、成本更低,並且能夠在一天內更頻繁運行資料處理流程,從而讓企業營運更加高效、更加同步。但在 AI 時代,過去的邏輯正在發生變化,未來不僅人類會使用這些資料,AI 系統和 Agent 也會直接訪問和使用結構化資料庫,而 AI 的處理速度遠遠快於人類,這意味著資料處理基礎設施必須獲得數量級的效能提升。
與此同時,另一類更龐大的資料也正在成為 AI 時代的重要資源「非結構化資料」。黃仁勳指出,PDF 文件、影片、語音和演講內容等等,都屬於非結構化資料。
全球每年產生的資料中,大約 90% 都是非結構化資料。在很長一段時間裡,這些資料幾乎無法被系統有效利用,人們只是閱讀這些內容,然後把它們儲存在檔案中,卻很難對其進行查詢和搜尋。
其根本原因在於,非結構化資料缺乏可直接建立索引的結構,要使用這些資料,首先必須理解其語意和目的。 而 AI 的多模態理解能力正在改變這一狀況。正如 AI 已經在多模態感知和理解方面取得突破一樣,同樣的技術可以用於讀取 PDF、理解影片和語音內容,並將其語意資訊嵌入到可計算的資料結構中,從而使這些資料能夠被搜尋、查詢和分析。
換句話說,AI 正在把原本難以利用的海量非結構化資料轉化為可計算的資訊資源。 為了支持這一轉變,NVIDIA 構建了兩項基礎技術。黃仁勳表示,就像當年為 3D 圖形計算推出的 RTX 技術一樣,NVIDIA 現在為資料處理打造了新的軟體庫。
其中 cuDF 用於加速資料運算,主要面向結構化資料處理;而 cuVS 則用於處理非結構化資料和 AI 資料。這兩項技術將成為未來資料基礎設施中最重要的平台之一。 黃仁勳透露,目前這兩項技術正在逐步融入全球複雜的資料處理生態系統。由於資料處理產業已經發展了數十年,圍繞它已經形成了大量公司、平台和服務,因此將新的加速技術深度整合進整個生態需要時間。
但 NVIDIA 已經看到越來越多的合作夥伴開始採用這些技術。 例如 IBM SQL 的發明者之一,也是歷史上最重要資料庫技術的推動者——正在利用 cuDF 來加速其資料平台 IBM watsonx.data。在黃仁勳看來,這類合作標誌著 AI 正在逐步重塑整個資料處理基礎設施,使企業能夠同時高效利用結構化資料和海量的非結構化資料。

兆元美元的信心
AI 重塑整個基礎設施的另一個標誌是這兩年湧現出海量的 AI 企業。
去年,這個行業經歷了史無前例的飛躍。風險投資對新創公司的投入高達 1500 億美元,創人類歷史之最。投資規模也從千萬美元級躍升至數十億美金級。究其原因,是這些公司都需要海量算力和 Token。
無論它們是創造 Token 還是為 Token 增值,它們對算力的渴望是相同的。 黃仁勳表示,「正如 PC、網際網路、行動雲革命催生了 Google、Amazon 和 Meta,這次運算平台的遷移也將孕育出一批對未來世界至關重要的新巨頭。」
那為什麼這種 AI 企業的爆發會發生在這兩年?因為發生了三件大事。
ChatGPT 開啟生成式 AI 時代: 計算從「基於檢索」轉向「基於生成」。這徹底改變了電腦的架構、供應和建設方式。
推理 AI(o1/o3)的出現: AI 開始擁有反思、規劃、拆解問題的能力。o1 讓生成式 AI 變得可靠且基於事實。為了「思考」,輸入和輸出 Token 的使用量呈爆炸式增長。
Claude Code 開啟代理時代: 這是首個代理模型。它能閱讀文件、編碼、編譯、測試並迭代。它革新了軟體工程。現在 NVIDIA 內部每個工程師都在使用 AI 代理輔助程式設計。
黃仁勳表示,「AI 已經從“感知”進化到“生成”,再到“推理”,現在已經可以執行極其高效的工作。 “推理拐點”已經到來。 AI 要思考、要行動、要閱讀、要推理,每一環都在進行推理。現在已經遠超訓練階段,進入了推理的疆場。過去兩年,計算需求增長了約 10,000 倍,而使用量增長了約 100 倍。我深感這兩年的計算需求實際增長了 100 萬倍。」
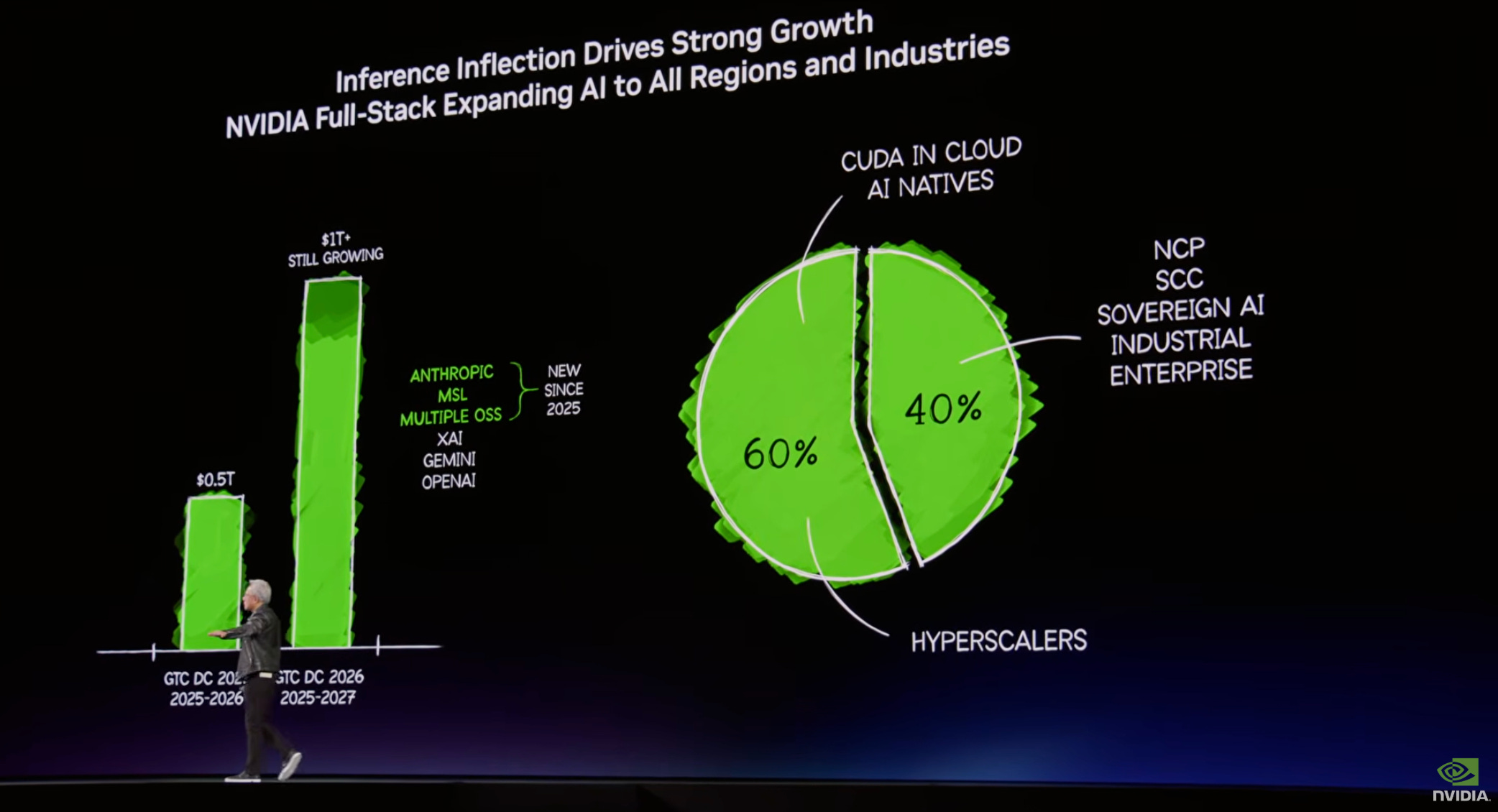
緊接著,老黃又分享了幾個資料,讓現場的氣氛達到了高潮。 他高興的向觀眾分享道,「去年我說 Blackwell 和 Rubin 到 2026 年的訂單額將達 5000 億美元,你們可能沒覺得驚艷。但今天,在這裡,我預見 2027 年的營收將至少達到 1 兆美元。」
他進一步強調了這不是空話,因為計算需求只會更高。
2025 年是 NVIDIA 的「推理之年」,NVIDIA 系統是全球成本最低的 AI 基礎設施,使用壽命越長,成本就越低。 目前全球三分之一的 AI 計算開源模型(如 Anthropic 和 Meta 的模型)都跑在輝達晶片上。NVIDIA 是全球唯一能運行 AI 所有領域的平台,從語言、生物、圖形、視覺,到機器人、基因科學、蛋白質結構或雲端服務等。
在輝達的業務中 60% 來自頂級雲端服務商,另外 40% 則遍布區域雲、國家級 AI、企業級伺服器及工業自動化。
全球最低的Token 成本
黃仁勳介紹了 NVIDIA 在 AI 推理基礎設施上的最新進展。他表示 AI 效能的突破並不僅來自單一技術,而是由運算架構、軟體堆疊和演算法的系統級協同設計共同推動。NVIDIA 推出的 NVFP4(FP4)計算體系不僅是一種更低精度的資料格式,而是一種全新的 Tensor Core 計算架構。
通過 NVFP4,NVIDIA 已經實現了在推理階段幾乎不損失精度的情況下,大幅提升效能和能效,同時這一計算格式也開始應用於模型訓練。 結合 NVLink 72 高速互連,以及 Dynamo、TensorRT-LLM 等軟體最佳化,NVIDIA 構建起一套面向大模型推理的完整技術體系。為了最佳化底層軟體與 GPU,公司還投入數十億美元建設 NVIDIA DGX Cloud 超級運算平台,用於開發和優化 AI 推理的軟體堆疊。
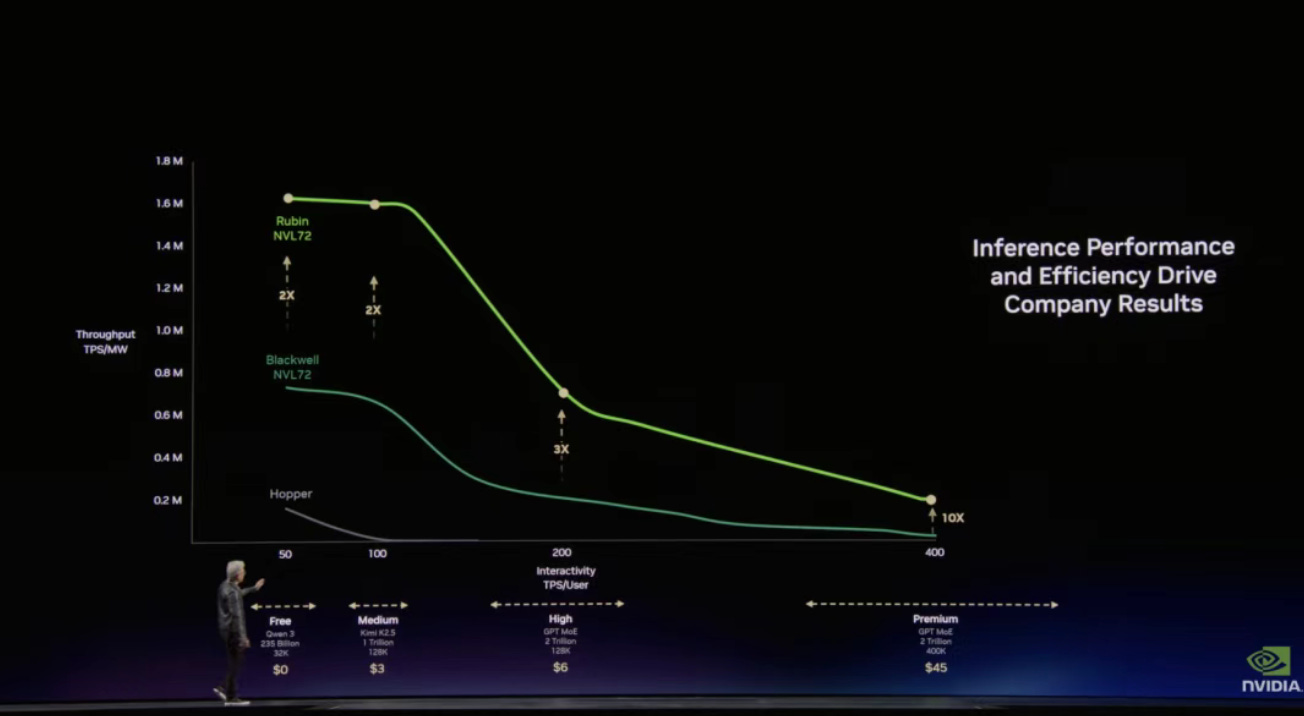
黃仁勳強調,很多人曾經認為推理是 AI 系統中最簡單的部分,但實際上推理既是最困難的環節,也是最重要的商業環節,因為它直接決定 AI 服務的收入來源。根據研究機構 SemiAnalysis 的評測,在資料中心層面,衡量 AI 系統效率的指標是每瓦特能夠生成多少 token(tokens per watt)。
由於數據中心受到電力等物理條件限制,本質上更像一個「AI 工廠」,企業必須在固定功率下盡可能多地生產 token。 評測結果顯示 NVIDIA 在 AI 推理效能和效率上依然保持領先。按照傳統的摩爾定律,新一代晶片通常只能帶來約 1.5 倍的效能提升,但從 Hopper H200 到 Grace Blackwell NVLink 72 架構,NVIDIA 的每瓦特效能提升約 35 倍。這一架構也帶來了更低的 token 成本,在當前市場上有明顯優勢。
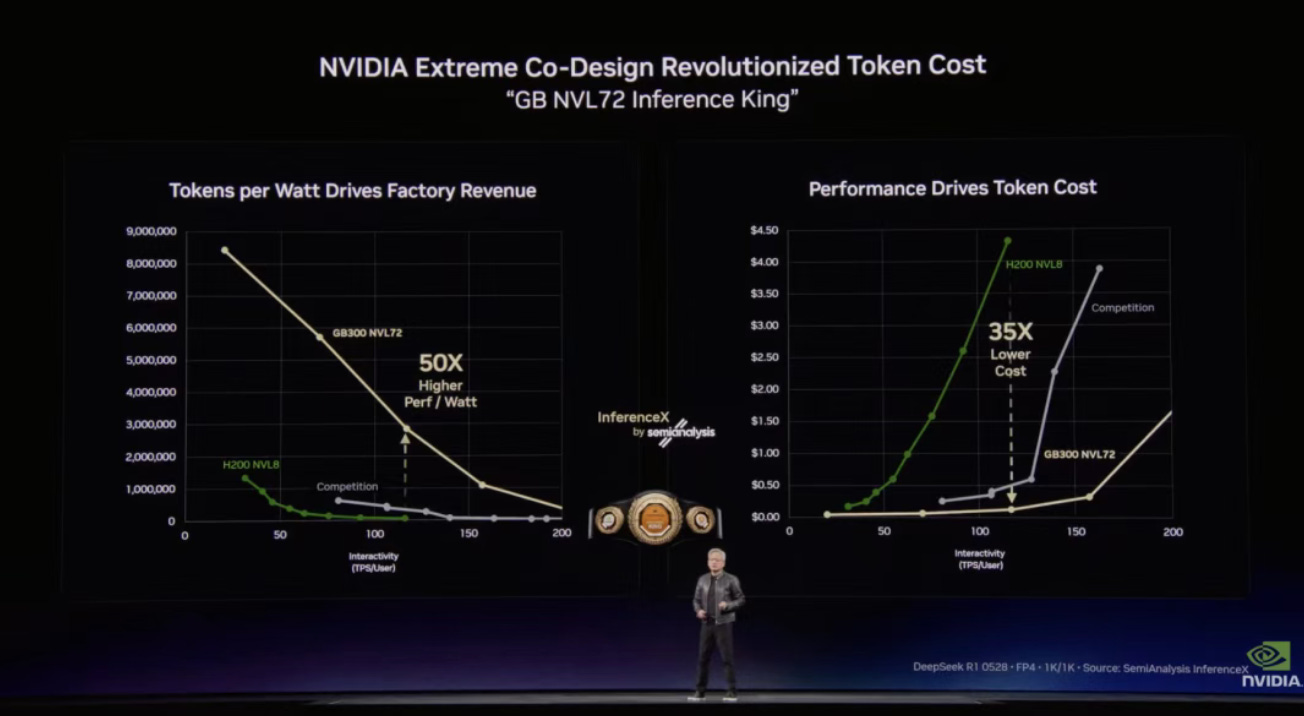
黃仁勳表示,極致的軟硬體協同設計還能顯著提升現有系統效能。例如在部分 AI 推理平台中,僅通過更新 NVIDIA 軟體堆疊,就能將生成速度從約 700 token/ 秒提升至接近 5000 token/ 秒,效能提升約 7 倍。 黃仁勳強調,NVIDIA 的 Token 成本在世界範圍內是「不可觸碰」的。 即使競爭對手的架構是免費的,它也不夠便宜。因為建立一個 1GW 的工廠,即使裡面什麼都不放,15 年的攤銷成本也高達 400 億美元。投資人必須確保在這個工廠裡運行最強的電腦系統,才能獲得最低的 Token 生產成本。
在他看來,數據中心也正在發生變化,過去是儲存和運算中心,而未來將成為生產 token 的 AI 工廠。隨著 AI 繼續普及,無論是雲端廠商、AI 公司還是傳統企業,都將開始從「Token 工廠效率」的角度來衡量自己的計算基礎設施,因為在 AI 時代,token 將成為新的數位商品,而計算能力則決定企業創造價值的能力。
Vera Rubin 時代降臨
一個全新的計算平台,由七款晶片組成, 涵蓋計算、網路和儲存三大功能,是目前最先進的 POD 規模 AI 平台。平台包含 40 個機櫃、1.2 千萬億個電晶體、近 2 萬個 NVIDIA 晶片、1152 個 NVIDIA Rubin GPU、60 exaflops 的運算能力以及 10 PB/s 的總擴展頻寬。目前已全面投產,並得到了包括 Anthropic、OpenAI、Meta 和 Mistral AI 以及所有主要雲端供應商在內的眾多客戶的支持。
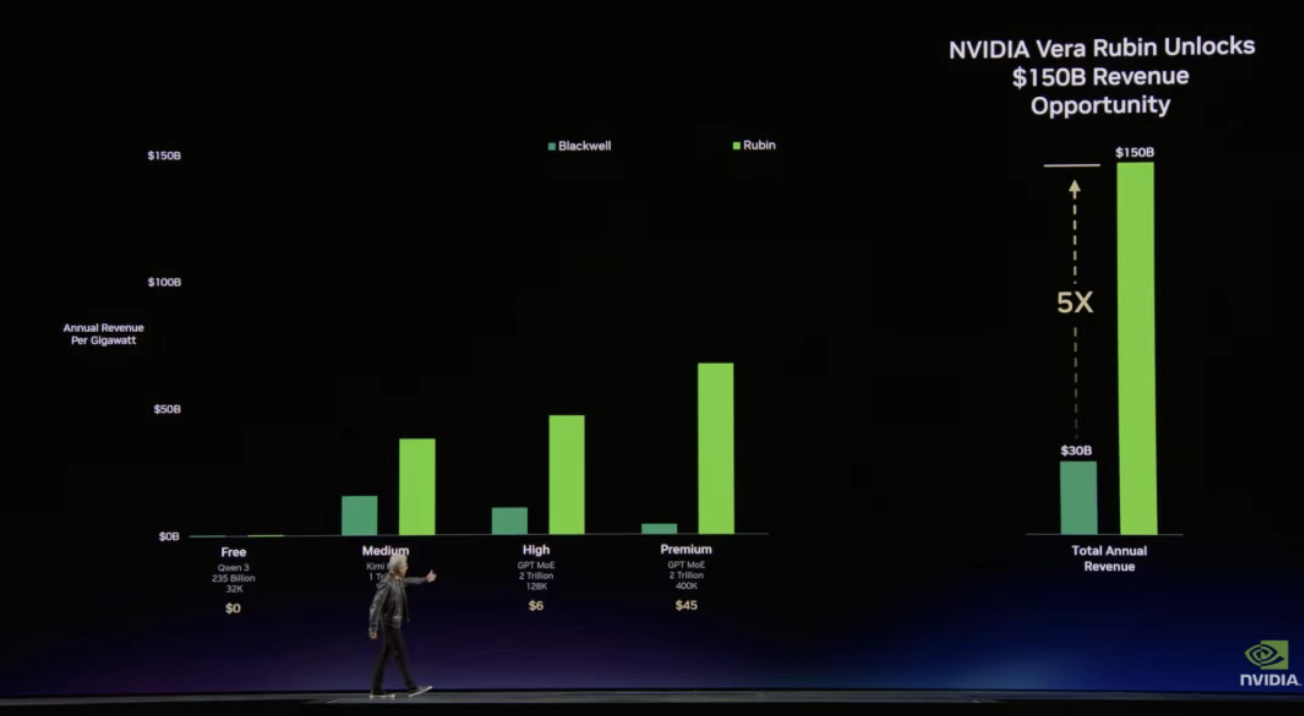
過去十年間 AI 計算能力已經實現了約 4000 萬倍的提升,而這一變化正推動數據中心向「AI 超級電腦」的形態演進。
「過去我發布產品時,可能只是手裡舉著一塊晶片;但現在當我談到 Vera Rubin 時,我說的是一個全端垂直整合的龐大系統。」

NVIDIA 最新的 Vera Rubin AI Supercomputer 系統是一套從硬體到軟體完全縱向整合的計算平台,專門為 Agentic AI 設計。隨著大語言模型不斷擴大規模、生成更多 token 並處理更長的上下文,系統不僅需要更強的計算能力,還需要更高頻寬的記憶體和儲存訪問能力,例如 KV Cache、結構化資料處理 cuDF 以及非結構化向量資料 cuVS 等。因此,NVIDIA 對整個系統架構進行了重新設計,包括計算、儲存和網路。
在硬體層面,NVIDIA 為這一個平台開發了一款全新的數據中心 CPU「NVIDIA Vera CPU」。該處理器針對極高的單執行緒效能、大規模資料處理能力以及能效最佳化,並成為全球首個在數據中心中採用 LPDDR5 記憶體的 CPU,從而實現領先市場的效能功耗比。
黃仁勳透露,這款 CPU 已經開始單獨銷售,並有望成為 NVIDIA 數十億美元級的業務。 在系統設計方面,Vera Rubin 超級電腦採用 100% 液冷架構,並通過 45°C 熱水散熱,大幅降低數據中心散熱成本。同時系統內部的線路被大幅簡化,使得整機安裝時間從過去的兩天縮短至約兩小時,顯著提升數據中心部署效率。
網路互連是這一系統的關鍵技術之一。NVIDIA 在該平台上部署了第六代 NVLink 互連架構,實現 GPU 之間的高速擴展連接。黃仁勳表示是目前全球最先進、實現難度最高的大規模 GPU 互連系統之一。
此外,NVIDIA 還推出了全球首個 CPO 光電共封裝的 NVIDIA Spectrum-X Ethernet Switch,將光模組直接整合到晶片封裝中,實現電子訊號與光訊號可以直接轉換,從而大幅提升數據中心網路頻寬與能效。這項技術是由 NVIDIA 與台積電共同開發,目前已經進入量產階段。
在更大規模的系統擴展上,NVIDIA 還展示了 Rubin Ultra Compute System。該系統通過新的 Kyber 機櫃架構,可以在一個 NVLink 域中連接 144 個 GPU,形成一台規模極大但架構統一的電腦,通過中板結構連接,突破傳統銅纜互連的距離限制。
黃仁勳表示,隨著 AI 模型規模和推理需求持續增長,未來的數據中心將越來越像一台 完整的超級電腦。而像 Vera Rubin 這樣的系統,正是為下一代 AI 工作做準備。
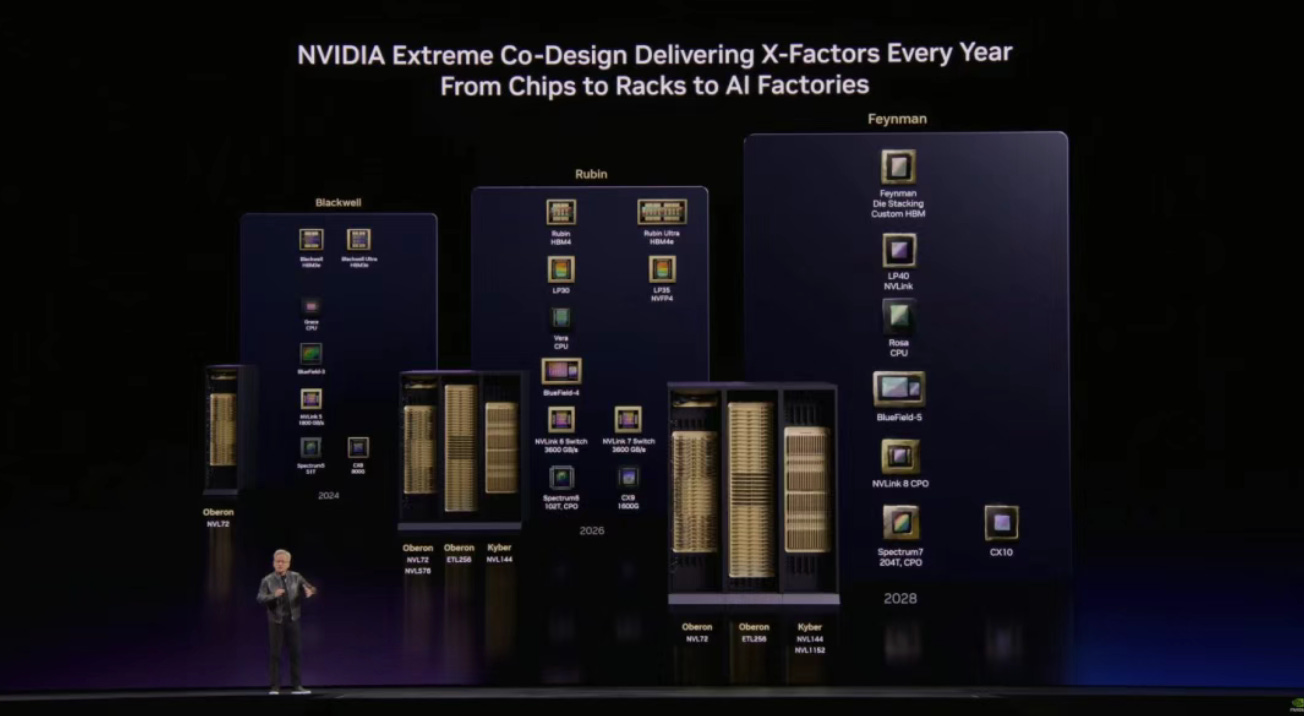
Feynman 前瞻
輝達也預告了下一代 Feynman GPU 架構的細節。為了突破 AI 推理的儲存瓶頸,輝達改變了以往使用標準 HBM 的策略:
客製化 HBM: Feynman 將跳過通用規格,採用基於 HBM4E 的客製化增強版,甚至提前佈局客製化 HBM5 方案。允許將部分 GPU 資料處理邏輯直接嵌入儲存底層的晶圓(Base Die)中。
全新 Rosa CPU: Feynman 平台將搭載代號為 Rosa 的全新 CPU。Rosa CPU 被設計為 Agentic AI 的編排中樞,能更高效地調度 Token 流動。
Rosa 架構致敬了美國物理學家、諾貝爾獎得主 Rosalyn Sussman Yalow,同時也呼應了發現 DNA 結構的 Rosalind Franklin。

NVIDIA DSX
在 AI 基礎設施的建設中,輝達引入了數位孿生模擬系統。
虛擬調試: 使用 Siemens、Cadence 和 NVIDIA DSX Air 進行熱力、電力與網路模擬,大幅縮短數據中心建設週期。
基礎設施作業系統: 當數據中心運行後,AI 會與 NVIDIA DSX MaxQ 協同運作,即時動態調度冷卻、電力與網路系統以達到最佳效能。

太空部署: 輝達正與合作夥伴開發太空運算平台 Vera Rubin Space One,計劃在軌道上建設數據中心。
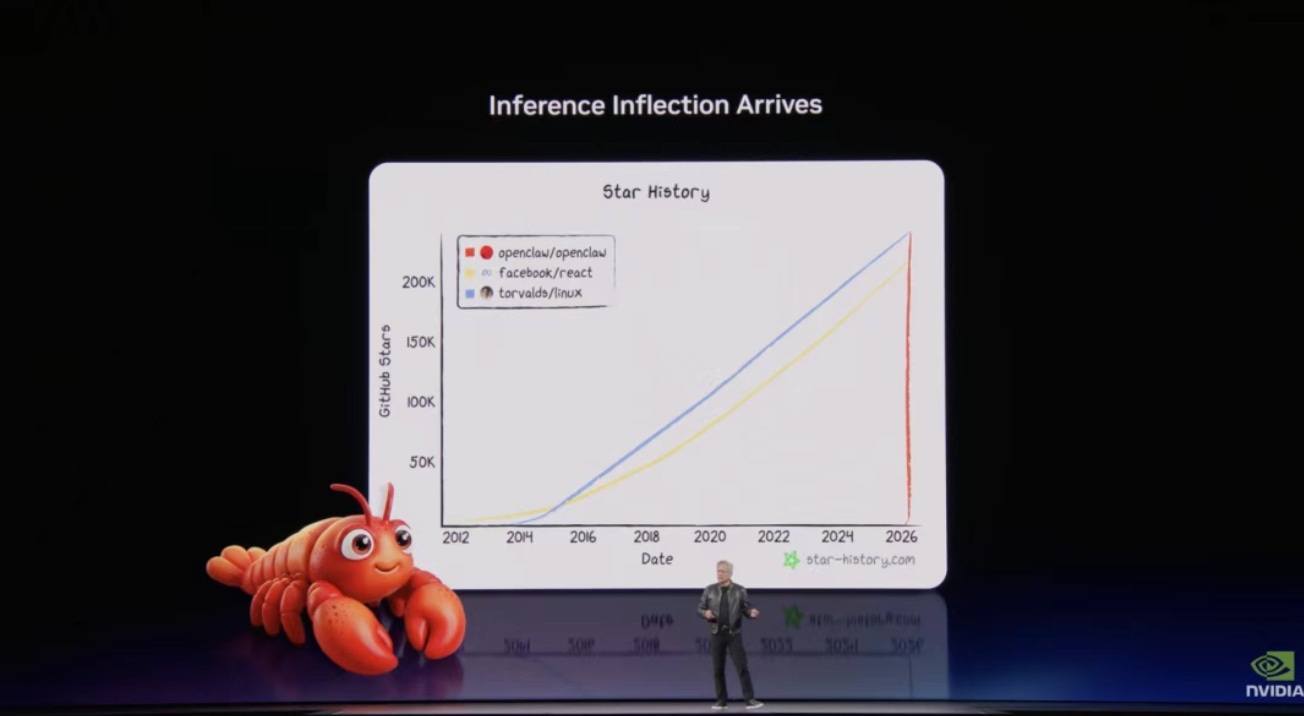
推出 NemoClaw
黃仁勳高度評價了由 Peter Steinberger 創建的 OpenClaw。 黃仁勳表示 OpenClaw 的增長速度甚至超過了 Linux 在過去幾十年的傳播速度,對整個行業的影響力非常深遠。
AI 大佬 Andrej Karpathy 最近提出的一種「AI 研究助手」模式很好的體現 Agent 系統的能力,用戶只需給 AI 一個任務,然後去休息,AI 便可以在後台自動運行數十甚至上百個實驗,不斷保留有效結果、淘汰無效方案。
類似的案例正在不斷出現。例如有人將 OpenClaw 安裝在自己父親的設備上,通過藍牙連接釀酒設備,實現從生產流程到網站訂單系統的全流程自動化,甚至在深圳已經出現用戶排隊購買相關產品的案例。隨著這一專案迅速流行,社群甚至已經開始舉辦專門的開發者活動,足以說明他的熱度。
從技術上看 OpenClaw 可以被理解為 Agentic AI 的作業系統。它能夠連接大語言模型,管理各種計算資源,並呼叫檔案系統、工具和模型服務;同時具備任務調度能力,可以將複雜問題分解為多個步驟,並呼叫 Sub-Agentic AI 協同完成任務。
此外,它還提供多模態輸入輸出能力,用戶既可以通過文字、語音甚至手勢和他交互,也可以通過訊息、郵件等方式獲得反饋。 正因如此,OpenClaw 的意義類似於過去最基礎的軟體。就像 Linux 讓個人電腦和伺服器生態得以發展,Kubernetes 推動了雲端運算時代的基礎設施,而 HTML 構建了網際網路應用基礎一樣,OpenClaw 為 Agent 時代提供了重要的軟體堆疊。
黃仁勳認為,未來所有科技公司和軟體公司都會面臨一個問題「你的 OpenClaw 戰略是什麼?」 因為企業軟體正在從傳統工具型軟體,轉向以 Agent 為核心的系統。 在傳統企業的 IT 架構中,數據中心主要負責儲存資料和運行應用程式,各類軟體系統通過工具和工作流為人類員工提供服務。
但在 AI 時代模式一定會發生變化。黃仁勳認為,未來幾乎所有 SaaS(Software as a Service) 公司都將演變為 AaaS(Agentic as a Service)。以 Agent 為核心的服務平台。 不過,AI 系統進入企業網路也會帶來了新的安全挑戰。因為這些系統不僅能夠訪問敏感資料,還可以執行程式代碼並與外部網路通信。未來如果缺乏安全機制,可能帶來嚴重風險。因此 NVIDIA 與 OpenClaw 作者 Peter Steinberger 以及多位安全計算專家合作,對系統進行了企業級安全擴展,並推出 NVIDIA NemoClaw。
該架構在 OpenClaw 基礎上加入了 OpenShell 的安全組件,並提供企業級策略執行、網路防護和隱私路由等能力,使企業能夠安全部署和運行 Agent 系統。同時系統還支持連接企業已有的策略引擎和治理工具,從而確保合規和資料安全的前提下運行 Agent。

開放模型生態
現實世界的需求高度多樣化,不可能由單一模型滿足所有行業。因此,開放模型正在形成一個規模龐大的 AI 生態系統,目前已經包含接近 300 萬個開放模型,覆蓋語言、視覺、生物、物理和自動駕駛等多個領域。
作為其中的重要貢獻者,NVIDIA 已發布多條開放模型產品線,包括 Nemotron(語言模型)、Cosmos World Foundation Model(世界模型)、Project GR00T(機器人基礎模型)、Drive AV Foundation Models(自動駕駛模型)、BioNeMo(數位生物學模型)以及 Earth-2(AI 物理與氣候模擬平台),並同時開放訓練資料、訓練方法和框架工具,推動整個 AI 生態的發展。
黃仁勳表示,NVIDIA 的開放模型之所以能夠在多個榜單中處於領先位置,不僅因為效能達到世界級水平,更重要的是公司會持續投入長期研發。
「我們不會停止改進這些模型,」
例如 Nemotron 模型已經從 Nemotron 3 走向 Nemotron 4,Cosmos World Foundation Model 也從 Cosmos 1 發展到 Cosmos 2,而機器人模型 Project GR00T 也在不斷迭代。
NVIDIA 的策略是「縱向整合、橫向開放」,在持續提升模型能力的同時,讓整個生態都能參與到 AI 發展中來。 他還展示了 Nemotron 3 在智慧體框架 OpenClaw 中的表現。根據公開評測資料,當前全球排名前三的模型均處於這一技術的前沿。
NVIDIA 不僅希望構建領先的基礎模型,更重要的是讓開發者能夠在此基礎上進行微調和後訓練,構建適用於不同領域的專用 AI 系統。
為此 NVIDIA 推出了 Nemotron 3 Ultra 作為新一代基礎模型,並希望藉此幫助各個國家和行業構建屬於自己的 「主權 AI」。 為了進一步推動這一生態,NVIDIA 在大會上宣布成立 Nemotron Coalition。
該聯盟將與多家技術公司合作,共同推進 Nemotron 系列模型的發展。參與合作的公司包括圖像技術公司 Black Forest Labs、AI 程式設計平台 Cursor、智慧體開發框架 LangChain、歐洲 AI 公司 Mistral AI、AI 搜尋平台 Perplexity AI、印度 AI 公司 Sarvam AI 以及 Thinking Machines Lab 等。
黃仁勳表示,隨著越來越多企業加入合作,AI 模型將能夠覆蓋從語言到生物、從物理到自動駕駛等廣泛領域。 在企業軟體層面,黃仁勳再次強調,未來所有公司都需要制定自己的 OpenClaw 計畫。隨著 Agent 系統的發展,傳統的 SaaS 軟體模式將逐漸轉向 Agentic as a Service(AaaS)。
企業不僅會使用 token 來增強員工生產力,還會通過 AI 工廠生產 token,並向客戶提供 AI Agent 服務。他甚至預測,未來科技公司招聘工程師時,除了薪資外,還會提供「token 配額」,因為擁有更多 AI 計算資源的工程師能夠獲得更高的生產效率。
除了數位 AI,NVIDIA 還在推進具身智能(Physical AI)。黃仁勳表示,目前全球幾乎所有機器人公司都在與 NVIDIA 合作,現場展示的機器人數量超過 100 台。NVIDIA 為機器人開發提供完整技術體系,包括訓練計算平台、合成資料與模擬平台,以及部署在機器人內部的計算系統。同時,公司還提供完整的軟體和模型生態,例如機器人模擬與訓練平台 NVIDIA Isaac Lab、世界模型 Cosmos World Foundation Model 以及機器人基礎模型 Project GR00T。
在自動駕駛領域,黃仁勳認為「自動駕駛的 ChatGPT 時刻已經到來」。基於 NVIDIA Drive AV 和相關模型,車輛現在已經具備推理能力,可以解釋自己的駕駛決策並執行語音指令。NVIDIA 還宣布新的 Robotaxi 合作夥伴,包括 BYD、Hyundai Motor Company、Nissan 和 Geely,這些公司每年合計生產約 1800 萬輛汽車。同時,NVIDIA 還將與 Uber 合作,在多個城市部署自動駕駛計程車網路。
在機器人產業方面,NVIDIA 正與 ABB、Universal Robots、KUKA 等企業合作,將 Physical AI 模型與模擬系統結合,用於自動化工業生產線。黃仁勳還提到,未來通訊基礎設施也將成為 AI 系統的一部分,例如電信巨頭 T-Mobile 的通訊塔未來可能演變為「機器人 AI 基地台」,能夠即時分析交通和網路情況並動態調整訊號。
在總結演講時,黃仁勳表示,AI 產業正同時經歷三大變革。
AI 推理與 AI 工廠
Agentic AI 系統革命
Physical AI 與機器人時代
隨著這些技術逐漸成熟,計算能力、AI 模型和基礎設施將共同推動全球產業進入新的發展階段。
謝謝B大彙整,這次GTC內容很豐富龐大🙏👍👍👍
非常詳細,太有心了,有些幾乎錯過的細節,都可以在這裡找回,很讚!